

Create a composite evaluator using the UI
You can create composite evaluators on a tracing project (for online evaluations) or a dataset (for offline evaluations). With composite evaluators in the UI, you can compute a weighted average or weighted sum of multiple evaluator scores, with configurable weights.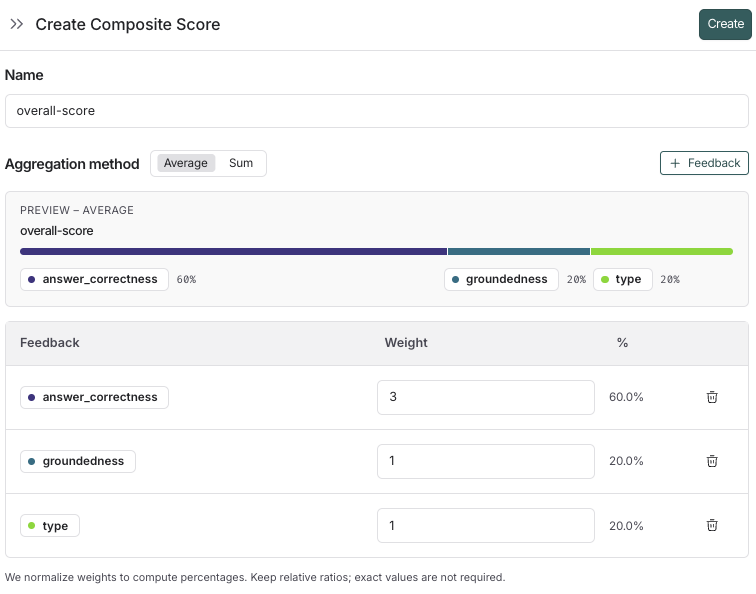

1. Navigate to the tracing project or dataset
To start configuring a composite evaluator, navigate to the Tracing Projects or Dataset & Experiments tab and select a project or dataset.- From within a tracing project: + New > Evaluator > Composite score
- From within a dataset: + Evaluator > Composite score
2. Configure the composite evaluator
- Name your evaluator.
- Select an aggregation method, either Average or Sum.
- Average: ∑(weight*score) / ∑(weight).
- Sum: ∑(weight*score).
- Add the feedback keys you want to include in the composite score.
- Add the weights for the feedback keys. By default, the weights are equal for each feedback key. Adjust the weights to increase or decrease the importance of specific feedback keys in the final score.
- Click Create to save the evaluator.
If you need to adjust the weights for the composite scores, they can be updated after the evaluator is created. The resulting scores will be updated for all runs that have the evaluator configured.
3. View composite evaluator results
Composite scores are attached to a run as feedback, similarly to feedback from a single evaluator. How you can view them depends on where the evaluation was run: On a tracing project:- Composite scores appear as feedback on runs.
- Filter for runs with a composite score, or where the composite score meets a certain threshold.
- Create a chart to visualize trends in the composite score over time.
- View the composite scores in the experiments tab. You can also filter and sort experiments based on the average composite score of their runs.
- Click into an experiment to view the composite score for each run.
If any of the constituent evaluators are not configured on the run, the composite score will not be calculated for that run.
Create composite feedback with the SDK
This guide describes setting up an evaluation that uses multiple evaluators and combines their scores with a custom aggregation function. Requires langsmith>=0.4.29
1. Configure evaluators on a dataset
Start by configuring your evaluators. In this example, the application generates a tweet from a blog introduction and uses three evaluators — summary, tone, and formatting — to assess the output. If you already have your own dataset with evaluators configured, you can skip this step.Configure evaluators on a dataset.
Configure evaluators on a dataset.
2. Create composite feedback
Create composite feedback that aggregates the individual evaluator scores using your custom function. This example uses a weighted average of the individual evaluator scores.Create a composite feedback.
Create a composite feedback.