

Alpha Notice: These docs cover the v1-alpha release. Content is incomplete and subject to change.For the latest stable version, see the current LangGraph Python or LangGraph JavaScript docs.
- Add short-term memory as a part of your agent’s state to enable multi-turn conversations.
- Add long-term memory to store user-specific or application-level data across sessions.
Add short-term memory
Short-term memory (thread-level persistence) enables agents to track multi-turn conversations. To add short-term memory:Use in production
In production, use a checkpointer backed by a database:Example: using Postgres checkpointer
Example: using Postgres checkpointer
You need to call
checkpointer.setup() the first time you’re using Postgres checkpointerExample: using [MongoDB](https://pypi.org/project/langgraph-checkpoint-mongodb/) checkpointer
Example: using [MongoDB](https://pypi.org/project/langgraph-checkpoint-mongodb/) checkpointer
Setup
To use the MongoDB checkpointer, you will need a MongoDB cluster. Follow this guide to create a cluster if you don’t already have one.
Example: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) checkpointer
Example: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) checkpointer
You need to call
checkpointer.setup() the first time you’re using Redis checkpointerUse in subgraphs
If your graph contains subgraphs, you only need to provide the checkpointer when compiling the parent graph. LangGraph will automatically propagate the checkpointer to the child subgraphs.Add long-term memory
Use long-term memory to store user-specific or application-specific data across conversations.Use in production
In production, use a store backed by a database:Example: using Postgres store
Example: using Postgres store
You need to call
store.setup() the first time you’re using Postgres storeExample: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) store
Example: using [Redis](https://pypi.org/project/langgraph-checkpoint-redis/) store
You need to call
store.setup() the first time you’re using Redis storeUse semantic search
Enable semantic search in your graph’s memory store to let graph agents search for items in the store by semantic similarity.Long-term memory with semantic search
Long-term memory with semantic search
Manage short-term memory
With short-term memory enabled, long conversations can exceed the LLM’s context window. Common solutions are:- Trim messages: Remove first or last N messages (before calling LLM)
- Delete messages from LangGraph state permanently
- Summarize messages: Summarize earlier messages in the history and replace them with a summary
- Manage checkpoints to store and retrieve message history
- Custom strategies (e.g., message filtering, etc.)
Trim messages
Most LLMs have a maximum supported context window (denominated in tokens). One way to decide when to truncate messages is to count the tokens in the message history and truncate whenever it approaches that limit. If you’re using LangChain, you can use the trim messages utility and specify the number of tokens to keep from the list, as well as thestrategy (e.g., keep the last maxTokens) to use for handling the boundary.
To trim message history, use the trim_messages function:
Full example: trim messages
Full example: trim messages
Delete messages
You can delete messages from the graph state to manage the message history. This is useful when you want to remove specific messages or clear the entire message history. To delete messages from the graph state, you can use theRemoveMessage. For RemoveMessage to work, you need to use a state key with add_messages reducer, like MessagesState.
To remove specific messages:
When deleting messages, make sure that the resulting message history is valid. Check the limitations of the LLM provider you’re using. For example:
- some providers expect message history to start with a
usermessage - most providers require
assistantmessages with tool calls to be followed by correspondingtoolresult messages.
Full example: delete messages
Full example: delete messages
Summarize messages
The problem with trimming or removing messages, as shown above, is that you may lose information from culling of the message queue. Because of this, some applications benefit from a more sophisticated approach of summarizing the message history using a chat model.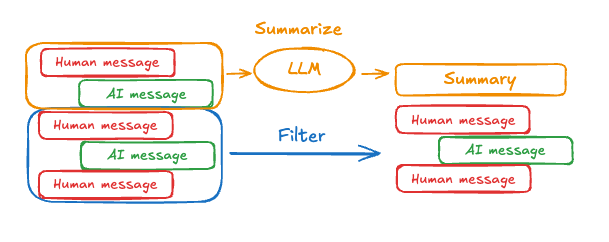
MessagesState to include a summary key:
summarize_conversation node can be called after some number of messages have accumulated in the messages state key.
Full example: summarize messages
Full example: summarize messages
- We will keep track of our running summary in the
contextfield
SummarizationNode).- Define private state that will be used only for filtering
call_model node.- We’re passing a private input state here to isolate the messages returned by the summarization node